Nachdokumentation einer Legacy Anwendung
Insights » Nachdokumentation einer Legacy Anwendung
Dieser Beitrag soll einen Überblick über eine standardisierte Vorgehensweise bei einer Nachdokumentation einer Legacy-Anwendung geben. Nur durch eine saubere Systemdokumentation des Altsystems können Risiken minimiert und Probleme bei der Umstellung auf ein neues System vermieden werden. Die Nachdokumentation wird anschließend nicht nur für die Konzeption des Ablösesystems benötigt, sondern oft auch für die Einschulung neuer Mitarbeiter, da das Legacy-System trotzdem noch einige Zeit gewartet werden muss.
Die Ablöse von Altsystemen (engl. „Legacy Systems“) stellt für viele Unternehmen eine große Herausforderung dar. Die Funktionalitäten, die in den letzten Jahrzehnten für diese Systeme entwickelt wurden, müssen in der Regel erhalten bleiben, jedoch soll auf eine moderne und zukunftsfähige Technologie umgestellt werden. In vielen Fällen ist gar nicht bekannt, welche Funktionalität überhaupt vorhanden ist und wie die Software technisch funktioniert. Gründe dafür können sein, dass die Entwickler schon lange nicht mehr im Unternehmen tätig sind oder dass die Software schlecht oder gar nicht dokumentiert ist. In diesem Artikel wird ein Ansatz für die technische und fachliche Nachdokumentation einer Legacy-Anwendung vorgestellt.
Im ersten Schritt werden die vorhandenen Dokumente analysiert und aufbereitet, um eine erste Einschätzung des Systems zu erhalten. Das System wird anschließend durch eine toolbasierte statische Codeanalyse untersucht, um den Umfang und die Kernelemente des Systems besser einschätzen zu können. Ferner wird die manuelle Codeanalyse als Ergänzung bzw. Erweiterung eingesetzt, wenn die toolbasierte Codeanalyse alleine nicht die entsprechenden Details oder Prioritäten erkennen kann. Bei besonders komplexen Funktionalitäten wird zur Gänze auf die Toolunterstützung verzichtet und rein manuell analysiert bzw. dokumentiert. Die Einstiegspunkte für die einzelnen Kernfunktionalitäten müssen gemeinsam in Expertenworkshops identifiziert und festgelegt werden. Außerdem wird bei den Expertenworkshops folgendes besprochen:
Gesamtarchitektur und Aufteilung der Kernfunktionalitäten auf Detaildokumente
- Prioritäten von Programmteilen, Methoden und Algorithmen
- Abstraktionsebene der Dokumentation im Hinblick auf mögliche Adressaten
- Um die Qualität sicherzustellen, findet nach jeder Iteration ein Review statt.
Unterschiedliche Dokumentationsstile wurden je nach Programmteil und Komplexität verwendet. Der größte Teil der Dokumentation besteht aus 1) manueller schrittweiser Dokumentation, 2) Code Snippets, 3) Ablaufdiagramme und 4) Pseudocode.
1
Bei der manuellen schrittweisen Dokumentation wird der Sourcecode im Detail (Zeile für Zeile) analysiert und fachlich relevante Codezeilen werden in die Dokumentation aufgenommen. Zeilen, die nur für die Programmausführung relevant sind, werden nicht berücksichtigt. Komplexe Funktionen werden bis zu einer festgelegten Detailtiefe (z.B. 3 Ebenen) analysiert. Hilfsfunktionen, allgemeine Funktionen oder programmiersprachenspezifische Funktionen werden weggelassen, da sie für die Dokumentation aus fachlicher Sicht nicht relevant sind. Zeilen, die schlussendlich berücksichtigt werde, werden textuell beschrieben.
2
Im Gegensatz zu 1) können Codeblöcke zusammengefasst werden und als Ganzes textuell beschrieben werden. Das macht z.B. Sinn, um Algorithmen zu beschreiben. Hier wäre die Beschreibung der einzelnen Zeilen wenig sinnvoll. Code Snippets sind auch für zukünftige Entwickler sinnvoll, um bestimmte Programmblöcke zu verstehen.
3
Gesamte Use Cases oder Abläufe werden durch Ablaufdiagramme auf einer höheren Ebene als 1) oder 2) beschrieben. Ein Ablaufdiagramm verschafft einen Überblick, welche Schritte in welcher Reihenfolge bei einem bestimmten Use Case bzw. Modul ausgeführt werden.
4
Sind bestimmte Funktionen oder Codeblöcke sehr kompliziert oder umfangreich, macht es Sinn, den gesamten Block in Pseudocode zu übersetzen. Pseudocode ist programmiersprachenunabhängig und einfacher zu lesen. Im Pseudocode werden auch Schleifen und Verzweigungen abgebildet.
Neben der fachlichen Dokumentation muss auch eine technisch-architektonische Dokumentation durchgeführt werden. Das Gesamtsystem wird hierbei als Ganzes analysiert und in Komponenten eingeteilt. Typische Komponenten sind:
- Frontend oder Clients
- Geschäftslogik
- Serverfunktionalität
- Datenbasis und Zugriffslogik
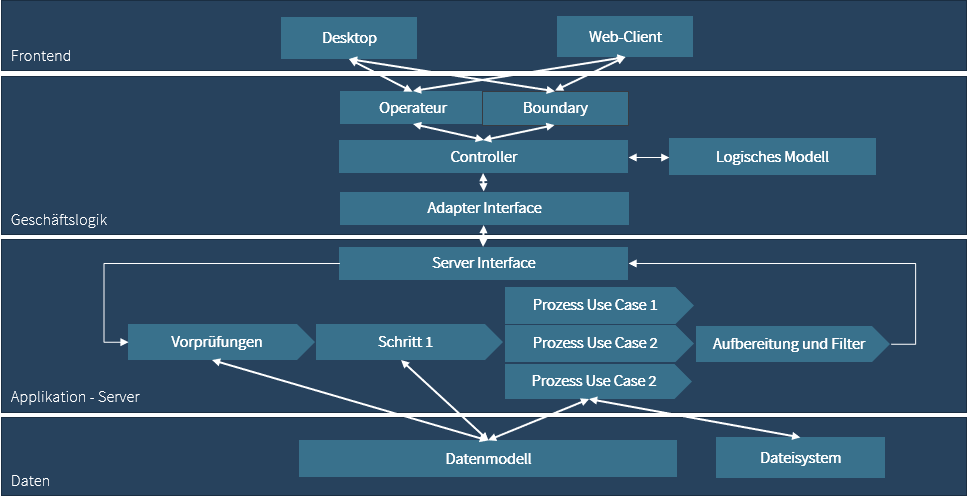
Diese einzelnen Komponenten und deren Schnittstellen werden technisch und in Form eines Architekturdiagramms dokumentiert. Für die Datenbasis ist es in einigen Fällen ratsam, eine eigene Detaildokumentation aufzubauen. Es muss auch unterschieden werden zwischen dem Datenmodell und den Daten selbst. Es kann gut sein, dass sich das Datenmodell nicht geändert hat, weil es auf Begriffe und Dinge der realen Welt basiert. Ein Beispiel dafür sind Personendaten, denn eine Person besitzt heute genauso wie vor 15 Jahren Adresse, Geburtsdatum oder Geschlecht. Das Datenmodell bleibt in solchen Fällen also ähnlich oder gleich, aber die Technologie für die Datenspeicherung und die Zugriffsmethodik ändern sich. Aufbauend auf dem Datenmodell besitzt jedes System eine (mehr oder weniger saubere) Objektstruktur, die den Zusammenhang der einzelnen Geschäftsobjekte darstellt. Die Dokumentation der Geschäftsobjekte wird folgendermaßen durchgeführt:
Im ersten Schritt werden die Top-Level-Objekte definiert und priorisiert. Ein typisches Top-Level-Objekt ist beispielsweise „Projekt“ und ein Projekt kann z.B. mehrere Aufgaben beinhalten. Auch die Objekthierachie wird dokumentiert. Je nach Priorisierung werden in dieser Form die relevanten Geschäftsobjekte beschrieben und rein technische, nicht fachlich relevante, Hilfsobjekte weggelassen. In der Detaildokumentation wird folgendes beschrieben und dokumentiert;
- Klassen und Attribute, Objekthierachie
- Aggregationen, Kompositionen
- Methoden, globale Funktionen
Ing. Philipp Schützeneder, MSc., PMP (Projektleiter, ReqPOOL)
Insights » Nachdokumentation einer Legacy Anwendung
Weitere Fachbeiträge ansehen
Christian Buchegger
Deutschland: +49 (0) 30 84415801
Österreich: +43 (0) 800 500122
E-Mail: office@reqpool.com
KONTAKTIEREN SIE UNS
Vereinbaren Sie ein unverbindliches Erstgespräch mit unserem Ansprechpartner

Christian Buchegger
Deutschland: +49 (0) 30 29 877 628
Österreich: +43 (0) 800-500-122
E-Mail:office@reqpool.com
